

Classification is a fundamental task in many fields, from computer vision and speech recognition to medical diagnosis and fraud detection. The ability to accurately categorize data into different classes is crucial for decision-making and problem-solving. With the explosion of big data, traditional machine learning algorithms may fall short in handling the complexity and variability of the data.
This is where deep learning comes in, offering powerful tools for classification tasks.
Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to learn representations of the input data. By automatically extracting relevant features and patterns from the data, deep learning models can achieve state-of-the-art performance in various tasks, including classification.
In this article, we will explore the topic of “Deep Learning Models for Classification.” Specifically, we will discuss the different types of classification models, their applications in real-world scenarios, the training and evaluation process, as well as the challenges and future directions of the field. By the end of this article, readers will have a better understanding of the importance of these classification models and their potential impact on various fields.
Fundamentals of Deep Learning
Neural networks are the backbone of deep learning, and they consist of interconnected nodes, or neurons, that process and transmit information. A neural network typically consists of multiple layers, including an input layer, one or more hidden layers, and an output layer. The input layer receives the raw data, such as images or text, and the output layer produces the desired output, such as a classification or prediction.
Each neuron in a neural network applies a mathematical function to its inputs and produces an output, which is then passed on to the next layer. Activation functions are an essential component of neural networks, as they introduce nonlinearity to the model. Nonlinear activation functions, such as sigmoid, ReLU, and tanh, allow neural networks to learn complex, nonlinear relationships between the input and output data.
When training a neural network, it is crucial to have a large and diverse dataset that represents the problem domain. The dataset is typically split into three sets: training data, validation data, and testing data. The training data is used to train the model by adjusting the weights and biases of the neurons to minimize the error between the predicted output and the actual output. The validation data is used to tune the hyperparameters of the model, such as the learning rate and the number of hidden layers, to prevent overfitting. The testing data is used to evaluate the performance of the model on unseen data and to estimate its generalization ability.
In summary, neural networks are composed of layers of interconnected neurons that process and transmit information. Activation functions introduce nonlinearity to the model, and training data, validation data, and testing data are used to train, tune, and evaluate the performance of the model.

Types of Deep Learning Models for Classification
Convolutional neural networks (CNNs)
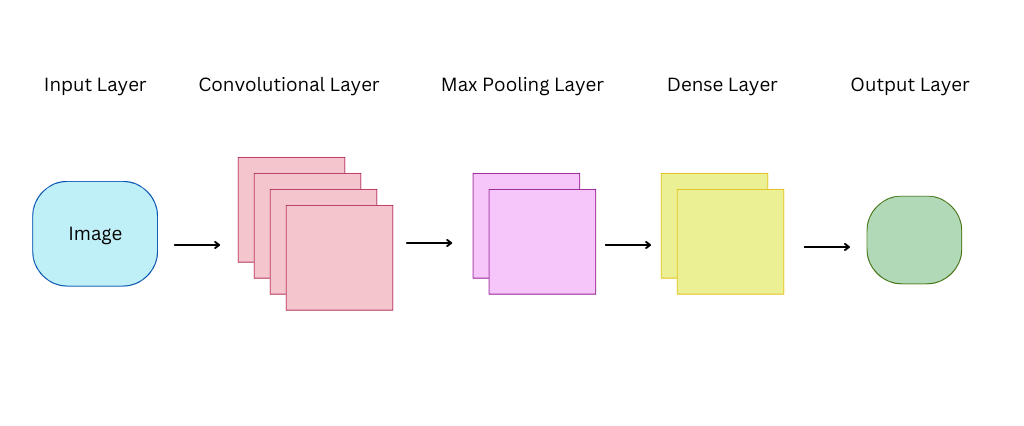
Convolutional neural networks (CNNs) are a type of deep learning model that is specifically designed for image classification. CNNs use convolution operations to extract features from images. These features are then used to classify the images. CNNs have been shown to be very effective for image classification tasks, such as classifying objects in images, detecting faces, and recognizing handwritten digits.
CNNs work by sliding a filter over the image, and computing the dot product of the filter and the image at each location. The filter learns to extract specific features from the image, such as edges, corners, and textures.
The output of the CNN is a feature map, which is a representation of the image that captures the important features. The feature map is then used to classify the image.
CNNs are also used for natural language processing tasks, such as text classification and machine translation. However, they are not as effective as RNNs for these tasks.
Recurrent neural networks (RNNs)
Recurrent neural networks (RNNs) are a type of deep learning model that is specifically designed for natural language processing tasks. RNNs can learn the sequential relationships between words in a sentence. This allows them to be used for tasks such as text classification and machine translation.
RNNs work by maintaining a state that captures the information from previous inputs. This state is then used to process the current input.
The output of the RNN is a representation of the sentence that captures the important sequential relationships. This representation can then be used to classify the sentence.
RNNs are also used for image classification tasks, such as classifying the emotions of people in images. However, they are not as effective as CNNs for these tasks.
Long short-term memory (LSTM) networks
Long short-term memory (LSTM) networks are a type of RNN that is specifically designed for tasks that require long-term memory. LSTMs can learn to remember information from previous inputs, which allows them to be used for tasks such as speech recognition and machine translation.
LSTMs work by using gates to control the flow of information in the network. These gates allow LSTMs to learn to remember information for long periods of time, even if the information is not immediately relevant.
LSTMs are the most effective RNNs for natural language processing tasks. They are also used for image classification tasks, such as classifying the emotions of people in images.
Generative adversarial networks (GANs)
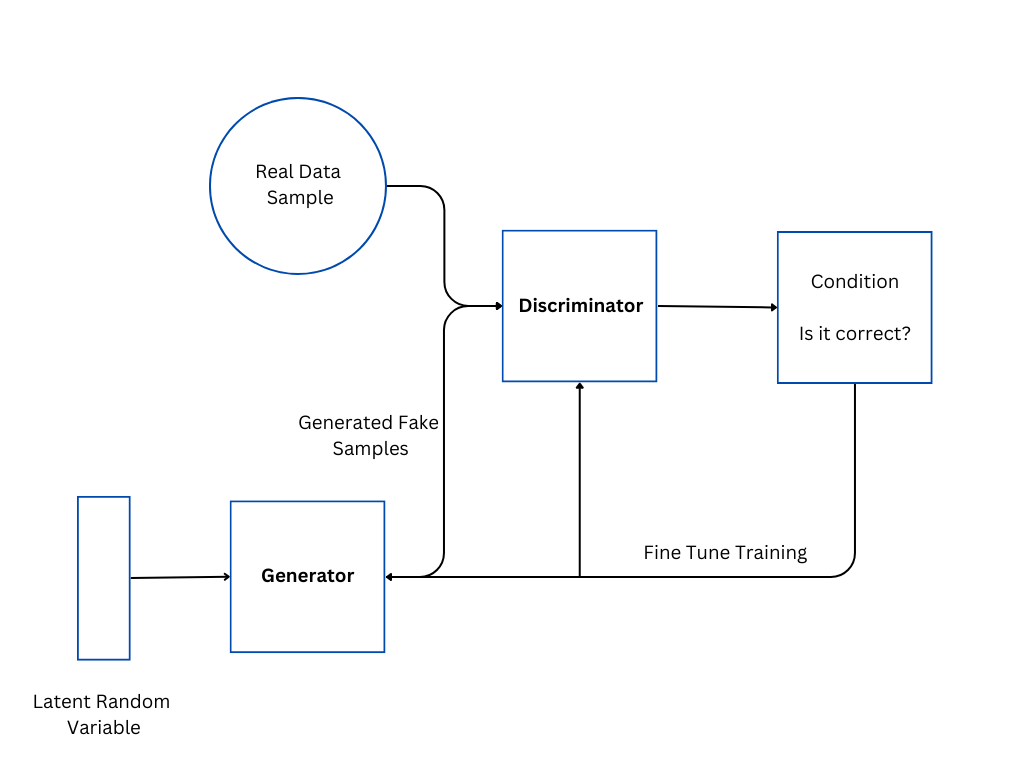
Generative adversarial networks (GANs) are a type of deep learning model that can be used for semi-supervised classification. Semi-supervised classification is the task of classifying data points when only a small fraction of the data points are labeled. GANs can be used to generate synthetic data that is similar to the real data. This synthetic data can then be used to train a classifier.
GANs work by pitting two neural networks against each other. One network, the generator, is responsible for generating synthetic data. The other network, the discriminator, is responsible for distinguishing between real and synthetic data.
The generator and discriminator are trained together in an adversarial manner. The generator tries to generate data that is indistinguishable from real data, while the discriminator tries to distinguish between real and synthetic data.
GANs are still a relatively new technology, and they are not yet widely used for classification tasks. However, they have the potential to be very effective for these tasks.
Deep belief networks (DBNs)
Deep belief networks (DBNs) are a type of deep learning model that is made up of multiple layers of restricted Boltzmann machines (RBMs). RBMs are a type of neural network that can learn to represent the probability distribution of a set of data. DBNs have been shown to be effective for a variety of classification tasks, such as image classification and natural language processing.
DBNs work by training RBMs in a bottom-up manner. The first RBM is trained on the raw data. The second RBM is then trained on the hidden representation of the first RBM, and so on.
DBNs are not as widely used as CNNs or RNNs for classification tasks. However, they can be effective for tasks where the data is sparse or noisy.
How Deep Learning Models Work?
Deep learning models are trained on a large amount of labeled data. Labeled data is data that has been classified into different categories. For example, if you are training a deep learning model to classify images of cats and dogs, the labeled data would consist of images that have been labeled as “cat” or “dog”.
The tech experts from the Molecula DeFi platform states that the training process for deep learning models is iterative. This means that the model is repeatedly updated with new data until it converges to a solution. In each iteration, the model is presented with a data point and its label.
The training process for deep learning models is iterative. This means that the model is repeatedly updated with new data until it converges to a solution. In each iteration, the model is presented with a data point and its label.
The model then uses its neural network to make a prediction about the label of the data point. The prediction is then compared to the actual label, and the model is updated to minimize the error between the prediction and the actual label.
The training process can be computationally expensive, especially for deep learning models with many layers. However, deep learning models have been shown to be very effective for a variety of tasks, such as image classification, natural language processing, and speech recognition.
The Training Process:
- Data Collection: The first step in training a deep learning model is to collect a dataset that consists of input data and corresponding target labels or outputs.
- Data Preprocessing: The collected data is then preprocessed, which may involve tasks such as normalization, resizing, and data augmentation to ensure the data is suitable for training.
- Model Architecture: The next step is to define the architecture of the deep learning model, which includes selecting the type of layers, the number of layers, and the connections between them.
- Loss Function: A loss function is defined to measure the difference between the predicted outputs and the true labels. The goal of the training process is to minimize this loss.
- Optimization: An optimization algorithm, such as gradient descent, is used to update the model’s parameters iteratively. This is done by computing the gradients of the loss function with respect to the model parameters and adjusting the parameters in the direction that minimizes the loss.
- Backpropagation: During the optimization process, backpropagation is used to efficiently compute the gradients by propagating them from the output layer to the input layer.
- Training Loop: The training process involves repeatedly feeding batches of input data into the model, computing the loss, and updating the parameters using the optimization algorithm. This is done for a fixed number of iterations or until the model converges to a satisfactory level.
The Inference Process:
Once the deep learning model has been trained, it can be used for the inference process to make predictions or generate outputs on new, unseen data.
- Preprocessing: Similar to the training process, the input data for inference may need to go through preprocessing steps such as normalization or resizing to match the input requirements of the trained model.
- Forward Pass: The input data is passed through the trained model in a forward pass, where it goes through the layers and computations defined in the model architecture.
- Output Generation: The output of the model is generated based on the learned knowledge, which can be a classification label, a probability distribution, or even a generated image or text.
- Post-processing: In some cases, post-processing steps may be applied to the model’s output to refine or interpret the results.
It’s important to note that the training process is computationally intensive and time-consuming, often requiring powerful hardware and large amounts of data. Once the model is trained, the inference process is typically faster and more efficient, as it only involves the forward pass through the model without the need for parameter updates.
Challenges and Limitations for Deep Learning Models for Classification
| Challenges and Limitations | Description |
| Computational complexity | Deep learning models can be computationally expensive to train, especially for large datasets. This is because the model needs to learn the relationships between the features of the data, and this can be a very complex task. |
| Data requirements: | Deep learning models require a large amount of labeled data to train. This data can be difficult and expensive to collect, especially for rare or niche tasks. |
| Interpretability: | Deep learning models are often considered to be black boxes, meaning that it can be difficult to understand how they make their predictions. This can be a challenge for tasks where it is important to understand the reasoning behind the predictions, such as medical diagnosis or financial trading. |
| Overfitting | Deep learning models can be prone to overfitting, which is when the model learns the training data too well and is unable to generalize to new data. This can be caused by a number of factors, such as using a model that is too complex or not having enough training data. |
| Bias | Deep learning models can be biased, which means that they may make different predictions for different groups of people. This can be caused by a number of factors, such as the way the data is collected or the way the model is trained. |
| Security | Deep learning models can be vulnerable to security attacks, such as adversarial examples. Adversarial examples are inputs that are designed to fool the model into making a wrong prediction. |
Despite these challenges, deep learning models have been shown to be very effective for a variety of tasks. As the technology continues to develop, these challenges are likely to be addressed, making deep learning models even more powerful and versatile.
Tips for choosing the right deep learning model for your classification task.
- Consider the type of data you have:
The type of data you have will determine the type of model that is best suited for your task. For example, if you have image data, you would use a convolutional neural network (CNN). If you have text data, you would use a recurrent neural network (RNN).
- Consider the complexity of the task:
The complexity of the task will also determine the type of model that is best suited for your task. For example, if you are trying to classify images of cats and dogs, you could use a simple CNN. However, if you are trying to classify images of different breeds of dogs, you would need to use a more complex CNN.
- Consider the computational resources you have available:
The computational resources you have available will also determine the type of model that you can use. For example, if you have a powerful computer, you could use a large CNN. However, if you only have a laptop, you would need to use a smaller CNN.
- Consider the level of interpretability required:
The level of interpretability required will also determine the type of model that you can use. If you need to understand how the model makes its predictions, you would need to use a model that is more interpretable. However, if you do not need to understand how the model makes its predictions, you can use a model that is less interpretable.
Here are some additional tips:
- Experiment with different models:
It is a good idea to experiment with different models to see which one works best for your task.
- Use a validation set:
A validation set is a set of data that is not used to train the model. The validation set is used to evaluate the performance of the model and to select the best model.
- Use a holdout set:
A holdout set is a set of data that is not used to train or evaluate the model. The holdout set is used to test the performance of the model on unseen data.
The Future of Deep Learning for Classification
The future of deep learning for classification is promising and holds great potential. Deep learning models have already demonstrated impressive performance in various classification tasks, surpassing traditional machine learning algorithms in many cases. As technology continues to advance and computational resources become more accessible, we can expect further advancements in the field of deep learning for classification.
Advancements in Model Architectures:
Researchers are continuously developing new deep learning architectures specifically designed for classification tasks. These architectures often incorporate innovative techniques such as attention mechanisms, transformers, or capsule networks. These advancements aim to improve the model’s ability to capture complex patterns and relationships within the data, leading to higher accuracy and better generalization.
Transfer Learning and Pretrained Models:
Transfer learning, a technique where a pre-trained model is used as a starting point for a new classification task, has shown remarkable success. Pretrained models, such as those trained on large-scale datasets like ImageNet, can be fine-tuned on domain-specific data, enabling faster and more accurate model training, even with limited labeled data. This approach reduces the need for extensive training from scratch and allows for efficient knowledge transfer across different tasks and domains.
Explainable and Interpretable Models:
As deep learning models become increasingly complex, there is a growing need for interpretability and explainability. Researchers are actively working on developing techniques to make deep learning models more transparent and understandable. This includes methods such as attention visualization, saliency maps, and layer-wise relevance propagation (LRP), which aim to provide insights into how the model makes decisions and which features it focuses on during classification.
Integration with Other Technologies:
Deep learning for classification is also expected to benefit from advancements in other fields. For example, the integration of deep learning with natural language processing (NLP) has enabled the development of models that can process and classify text data more effectively. Similarly, the combination of deep learning with computer vision has led to significant progress in image classification and object detection tasks.
Ethical Considerations and Bias Mitigation:
As deep learning models become more prevalent in real-world applications, there is a growing concern about potential biases and ethical implications. Efforts are being made to address these issues by developing techniques for bias detection and mitigation, fairness-aware training, and transparent decision-making processes.
In conclusion, the future of deep learning for classification looks promising, with ongoing research and advancements in model architectures, transfer learning, interpretability, integration with other technologies, and ethical considerations. These advancements are expected to further improve the accuracy, efficiency, and fairness of deep learning models, making them invaluable tools for various classification tasks across different domains.
FAQs
- Is Bert a deep learning model?
Yes, BERT is a deep learning model that is specifically designed for natural language processing tasks, such as text classification and question answering. It is a bidirectional encoder, which means that it can learn the meaning of words from both the left and right context.
- Can you use CNN for classification?
Yes, CNNs can be used for classification tasks, such as image classification and object detection. They are particularly well-suited for tasks where the data has a grid-like structure, such as images.
- Which neural network is best for classification?
The best neural network for classification will depend on the specific task and the data. However, some of the most commonly used neural networks for classification include CNNs, RNNs, and LSTMs.
- Can we use CNN for classification?
Yes, CNNs can be used for classification tasks. They are particularly well-suited for tasks where the data has a grid-like structure, such as images.
- Which CNN model is best for image classification?
There is no single best CNN model for image classification. The best model will depend on the specific dataset and the desired accuracy. However, some of the most popular CNN models for image classification include AlexNet, VGGNet, ResNet, and InceptionNet.
- What is VGG16 model for classification?
VGG16 is a CNN model that is commonly used for image classification. It is a 16-layer model that was first introduced in 2014. VGG16 has been shown to be effective for a variety of image classification tasks, including object detection and face recognition.
- Which deep learning model is best for binary classification?
The best deep learning model for binary classification will depend on the specific dataset and the desired accuracy. However, some of the most commonly used deep learning models for binary classification include logistic regression, support vector machines, and neural networks.
- What are the 4 deep learning models?
There are many different deep learning models, but some of the most common ones include:
- Convolutional neural networks (CNNs)
- Recurrent neural networks (RNNs)
- Long short-term memory networks (LSTMs)
- Generative adversarial networks (GANs)
- Can I use deep learning for classification?
Yes, deep learning can be used for classification tasks. Deep learning models have been shown to be effective for a variety of classification tasks, such as image classification, text classification, and natural language processing.
- Which deep learning model is best for classification?
The best deep learning model for classification will depend on the specific task and the data. However, some of the most commonly used deep learning models for classification include CNNs, RNNs, and LSTMs.






