
TL;DR:
Unsupervised learning analyzes unlabeled data to find patterns and structures without supervision.
Key Concepts:
- Clustering: Groups similar data (e.g., customer segmentation).
- Dimensionality Reduction: Simplifies data (e.g., PCA, t-SNE).
- Anomaly Detection: Finds outliers (e.g., fraud detection).
- Feature Extraction: Identifies key features (e.g., autoencoders).
Applications:
- Recommender Systems (Netflix, Amazon)
- Image & Video Analysis (facial recognition)
- NLP (topic modeling, sentiment analysis)
- Fraud Detection (unusual transactions)
- Genomics (DNA clustering)
Challenges:
- No labels, making evaluation tricky
- Overfitting & scalability issues
- Hard to interpret results
🔍 Why it matters: Unsupervised learning powers AI breakthroughs, making it essential for data-driven insights and automation.
What is Unsupervised Learning?
Unsupervised learning is a type of machine learning where the algorithm learns from unlabeled data without any predefined target variable or explicit feedback. Unlike supervised learning, where the algorithm learns from labeled data, unsupervised learning focuses on finding patterns, relationships, and structures within the data on its own.
Why Unsupervised Learning?
Unsupervised learning plays a crucial role in AI and machine learning for several reasons:
- Data exploration and discovery: Unsupervised learning allows us to explore and discover hidden patterns, structures, and relationships in the data that may not be apparent through manual inspection. It helps uncover valuable insights and gain a deeper understanding of complex datasets.
- Feature extraction and engineering: Unsupervised learning techniques such as dimensionality reduction and feature extraction help in reducing the complexity of high-dimensional data. By identifying the most important features, these methods improve the efficiency and effectiveness of downstream tasks such as classification and clustering.
- Clustering and segmentation: Unsupervised learning enables the grouping and segmentation of similar data points into clusters. This helps in identifying distinct groups or categories within the data, aiding in tasks like customer segmentation, image recognition, and anomaly detection.
- Recommendation systems: Unsupervised learning algorithms are used to build recommendation systems that provide personalized recommendations to users based on their preferences and behavior. These systems analyze patterns in user data to suggest relevant products, movies, or content.
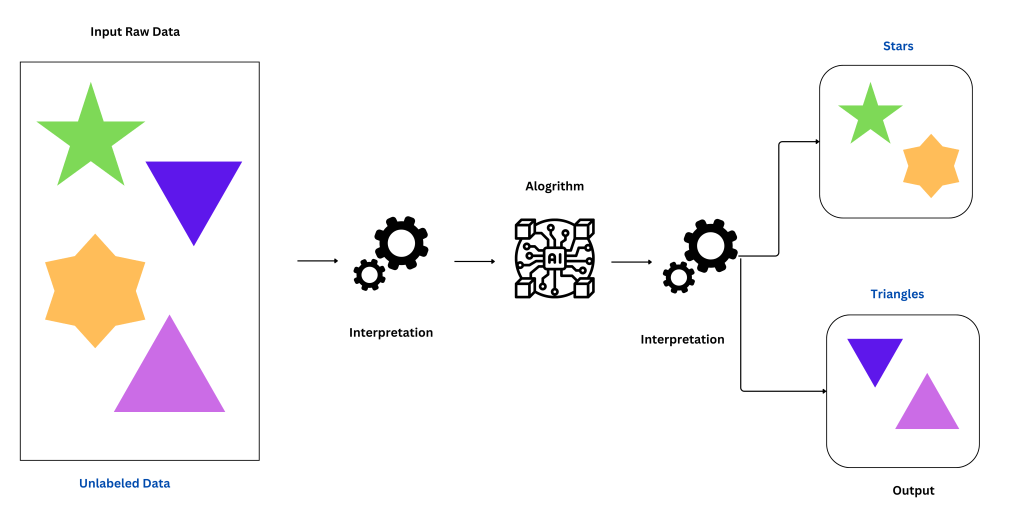
Brief overview of how unsupervised learning differs from other learning methods:
Unsupervised learning differs from other learning methods, such as supervised learning, in the following ways:
- Lack of labeled data: Unlike supervised learning, unsupervised learning does not rely on labeled data. It learns directly from unlabeled data, making it suitable for scenarios where labeled data is scarce or expensive to obtain.
- Training objectives: In supervised learning, the algorithm is trained to predict or classify a target variable based on labeled examples. In contrast, unsupervised learning focuses on finding patterns, structures, or clusters within the data without any predefined target variable.
- Evaluation: Evaluating the performance of unsupervised learning algorithms can be more challenging compared to supervised learning. Since there are no ground truth labels, evaluation metrics often rely on measures such as data coherence, clustering quality, or reconstruction accuracy.
Overall, unsupervised learning is an essential tool in the field of AI and machine learning, enabling us to extract valuable insights from unlabeled data and uncover hidden patterns and structures. Its ability to work with large, unannotated datasets makes it a powerful approach in various domains
What are the Key Concepts in Unsupervised Learning?
Clustering:
Clustering is a technique used in unsupervised learning to group similar data points together based on their similarities. The goal is to identify distinct clusters or categories within the data without any prior knowledge of the groups. Clustering algorithms, such as K-means or hierarchical clustering, analyze the patterns and relationships in the data to assign data points to clusters. It is commonly used in customer segmentation, image recognition, and social network analysis.
Dimensionality Reduction:
Dimensionality reduction is the process of reducing the number of features or variables in a dataset while preserving the most important information. In high-dimensional datasets, there may be redundant or irrelevant features that can negatively impact the performance of machine learning algorithms. Dimensionality reduction techniques, such as Principal Component Analysis (PCA) or t-SNE, transform the data into a lower-dimensional space by selecting the most informative features or creating new features that capture the essence of the data. It helps in visualizing and understanding complex datasets and improves the efficiency of subsequent analysis.
Anomaly Detection:
Anomaly detection involves identifying data points or patterns that deviate significantly from the expected behavior or normal data distribution. Unsupervised learning algorithms are used to detect outliers or anomalies in the data without any prior knowledge of the anomalies. Anomaly detection is used in various domains, such as fraud detection, network intrusion detection, and health monitoring, where detecting abnormal behavior is crucial.
Feature Extraction:
Feature extraction is the process of transforming raw data into a more compact and representative set of features. It aims to capture the most relevant information from the data while reducing noise and redundancy. Unsupervised learning techniques, such as autoencoders or deep belief networks, learn to extract meaningful features from unlabeled data by reconstructing or compressing the input data. These extracted features can then be used as input for downstream tasks, such as classification or clustering.
Examples and Real-World Applications of Each Concept:
- Clustering: Clustering is widely used in customer segmentation to identify groups of customers with similar preferences or behavior, allowing businesses to personalize marketing strategies. It is also used in image recognition to group similar images together, enabling applications like content-based image retrieval. In social network analysis, clustering can identify communities or groups of individuals with similar interests or connections.
- Dimensionality Reduction: Dimensionality reduction is used in various fields. In finance, it can help identify key variables that drive stock prices or market trends. In genomics, it aids in identifying genes that are most relevant to a particular disease. In natural language processing, dimensionality reduction techniques can be used to extract essential features from text data for sentiment analysis or document classification.
- Anomaly Detection: Anomaly detection has applications in fraud detection, where it helps identify unusual patterns or behaviors that indicate fraudulent activities. It is used in network intrusion detection to identify malicious activities or attacks that deviate from normal network behavior. Anomaly detection is also used in health monitoring to identify abnormal physiological or medical data that may indicate potential health risks.
- Feature Extraction: Feature extraction is used in various domains. In computer vision, it is used to extract features from images for tasks like object detection or facial recognition. In natural language processing, feature extraction techniques are used to represent textual data as numerical vectors, enabling tasks like sentiment analysis or document clustering. Feature extraction is also used in sensor data analysis for tasks like fault detection or predictive maintenance.
These concepts and their applications demonstrate the versatility and power of unsupervised learning in extracting valuable insights and patterns from unlabeled data, contributing to advancements in various fields.

What are the Techniques and Algorithms in Unsupervised Learning?
K-Means Clustering
K-means clustering is a simple and popular clustering algorithm. It works by dividing the data into k clusters, where k is a user-defined number. The algorithm starts by randomly assigning each data point to a cluster. Then, it iteratively moves the data points around so that they are closer to the center of their assigned cluster.
Hierarchical Clustering
Hierarchical clustering is a more complex clustering algorithm. It works by creating a hierarchy of clusters, where each cluster can be a parent or child of another cluster. The algorithm starts by creating a cluster for each data point. Then, it iteratively merges the clusters that are most similar to each other.
Principal Component Analysis (PCA)
PCA is a dimensionality reduction algorithm. It works by finding a lower-dimensional representation of the data that still captures the most important information. PCA is often used to reduce the size of datasets and to make them easier to visualize.
Autoencoders
Autoencoders are neural networks that can be used for feature extraction and reconstruction. They work by learning to compress the data into a lower-dimensional representation and then reconstruct the data from the compressed representation. Autoencoders can be used for a variety of tasks, such as image compression and denoising.
Gaussian Mixture Models (GMM)
GMMs are probabilistic models that can be used to model complex data distributions. They work by assuming that the data is a mixture of Gaussian distributions. GMMs can be used for a variety of tasks, such as clustering and anomaly detection.
Anomaly Detection Algorithms
Anomaly detection algorithms are used to identify outliers in data. They work by identifying data points that are significantly different from the rest of the data. Anomaly detection algorithms can be used to find fraud, errors, or other unusual events.
These are just a few of the many techniques and algorithms that are used in unsupervised learning. The best technique or algorithm to use will depend on the specific problem that you are trying to solve.
What are the Benefits and Challenges Of Unsupervised Learning?
| Benefits | Challenges |
| Enhanced data exploration and discovery: Unsupervised learning can be used to explore data and discover hidden patterns that would not be visible otherwise. This can be helpful for understanding the data and identifying new insights. | Overfitting: Unsupervised learning algorithms can sometimes overfit the data, which means that they learn the patterns in the training data too well and do not generalize well to new data. |
| Utilizing unlabeled data for training models: Unsupervised learning can be used to train models on unlabeled data. This can be helpful when labeled data is not available or when it is too expensive or time-consuming to collect. | Difficulty in evaluating performance: It can be difficult to evaluate the performance of unsupervised learning algorithms without ground truth labels. This is because there is no way to know for sure whether the patterns that the algorithm has found are actually meaningful. |
| Scalability: Unsupervised learning algorithms can be scaled to large datasets. This makes them suitable for applications where the amount of data is too large to be handled by supervised learning algorithms. | Interpretability: Unsupervised learning algorithms can be difficult to interpret, which means that it can be difficult to understand how the algorithm has made its decisions. This can be a challenge for applications where it is important to understand the reasons for the algorithm’s decisions. |
What are the Real World Applications of Unsupervised Learning?
Recommender systems
Recommender systems are a real-world application of unsupervised learning that personalize recommendations based on user behavior. These systems analyze user preferences and historical data to suggest items or content that users are likely to be interested in. Unsupervised learning techniques such as collaborative filtering and matrix factorization are commonly used in recommender systems to identify patterns and similarities in user preferences and make personalized recommendations.
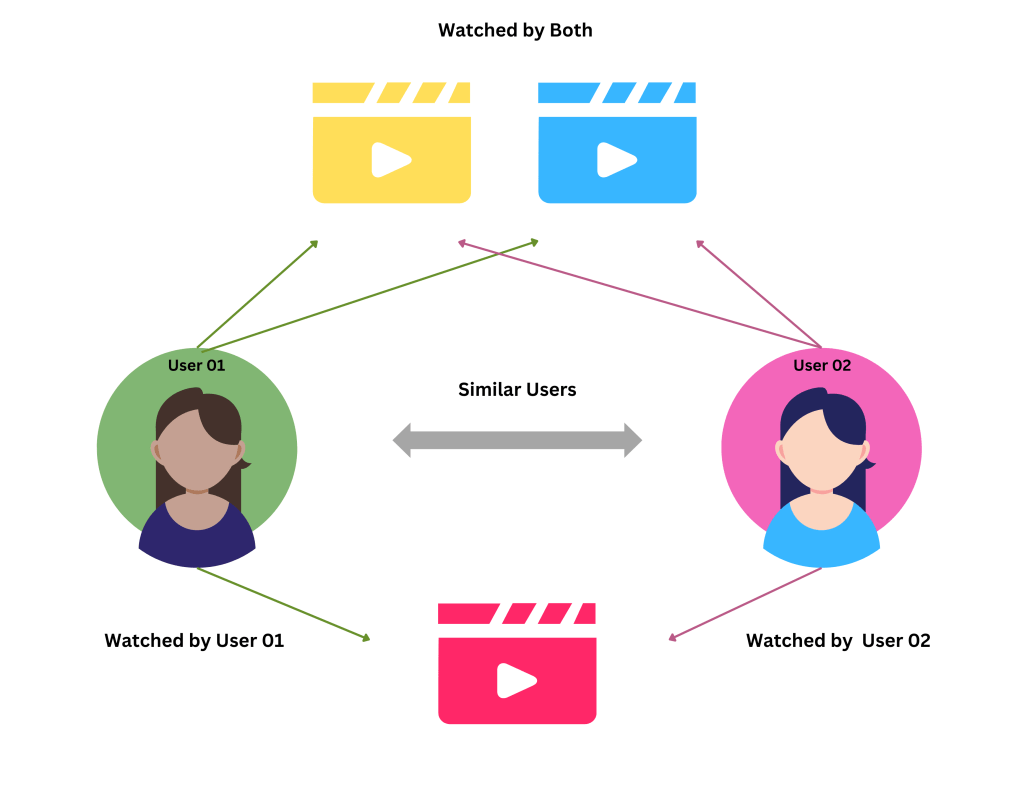
Image and video analysis
Image and video analysis is another practical application of unsupervised learning. Unsupervised learning algorithms can be used for tasks such as clustering and feature extraction to aid in object recognition and understanding visual content. By applying unsupervised learning techniques, images and videos can be automatically organized into meaningful categories or clusters, and relevant features can be extracted for further analysis or classification.
Natural language processing
Natural language processing (NLP) is a field that focuses on the interaction between computers and human language. Unsupervised learning plays a crucial role in NLP tasks such as topic modeling and sentiment analysis. Topic modeling algorithms, such as Latent Dirichlet Allocation (LDA), can automatically identify hidden topics in a collection of texts. Sentiment analysis techniques based on unsupervised learning can classify the sentiment or emotion expressed in a piece of text, allowing for automated analysis of customer reviews, social media posts, and other text data.
Fraud detection
Unsupervised learning techniques are widely used for fraud detection in various industries, including finance and e-commerce. By analyzing patterns and identifying unusual behaviors or outliers in financial transactions or user behavior data, unsupervised learning algorithms can help detect fraudulent activities. Anomalies or deviations from normal patterns can be identified using techniques such as clustering-based anomaly detection, which distinguishes normal behavior from unusual or fraudulent behavior.
Genomics
Genomics is an area of study that involves analyzing and understanding the structure, function, and evolution of genomes. Unsupervised learning algorithms can be applied to genomics data for tasks such as clustering DNA sequences. By clustering similar DNA sequences, unsupervised learning can aid in genetic analysis, identifying patterns, relationships, and variations in genomic data. This can lead to insights into genetic diseases, evolutionary relationships, and personalized medicine.
These real-world applications demonstrate the wide range of domains where unsupervised learning techniques can be applied to extract meaningful insights, discover patterns, and make predictions without the need for labeled data.
Final Thoughts
The key points discussed in the article include the real-world applications of unsupervised learning, such as recommender systems, image and video analysis, natural language processing, fraud detection, and genomics. These applications highlight the growing importance of unsupervised learning in various industries and its ability to extract meaningful insights and patterns without the need for labeled data.
The article also encourages further research and exploration in the field of unsupervised learning. With the continuous advancements in machine learning and artificial intelligence, there is a need to delve deeper into unsupervised learning techniques and algorithms to unlock their full potential and address challenges in areas such as scalability, interpretability, and generalizability.
Overall, the article emphasizes the significance of unsupervised learning in unlocking hidden patterns and making predictions in a wide range of domains, and it encourages researchers and practitioners to continue pushing the boundaries of unsupervised learning through research and development.
FAQs
- What is unsupervised learning with an example?
It is a type of machine learning where the model learns patterns and structures in data without any labeled examples. An example is clustering customer data to identify distinct groups based on their purchase behavior.
- What is a good example of unsupervised learning?
An example is dimensionality reduction techniques like Principal Component Analysis (PCA), which reduces the dimensionality of data while retaining important information.
- What are the two types of unsupervised learning?
The two types are clustering and dimensionality reduction. Clustering algorithms group similar data points together, while dimensionality reduction techniques reduce the number of variables in the data.
- What is the difference between supervised and unsupervised learning?
Supervised learning uses labeled data to train the model, while unsupervised learning uses unlabeled data. In supervised learning, the model learns to make predictions based on the input and output pairs, while in unsupervised learning, the model learns patterns and structures in the data without any specific outputs.
- Why is unsupervised learning used?
Unsupervised learning is used when there is no available labeled data or when the goal is to explore and understand the underlying structure of the data. It can also be used for data preprocessing and feature engineering tasks.
- Why is clustering called unsupervised learning?
Clustering is called unsupervised learning because it involves grouping similar data points together without any predefined labels or categories.
- What are examples of supervised and unsupervised learning?
Examples of supervised learning include classification and regression tasks, where the model is trained with labeled data. Examples include clustering, dimensionality reduction, and generative modeling.
- Can you think of four examples of unsupervised tasks?
Four examples of unsupervised tasks are clustering customer segments, anomaly detection in network traffic, topic modeling in natural language processing, and image compression using dimensionality reduction.
- What models are unsupervised learning?
Some popular models used in unsupervised learning include k-means clustering, hierarchical clustering, PCA, and autoencoders.
- Is CNN supervised or unsupervised?
Convolutional Neural Networks (CNNs) can be used for both supervised and unsupervised learning tasks. In supervised learning, CNNs are commonly used for image classification, while in unsupervised learning, they can be used for tasks like feature extraction or generative modeling.








